
Well, my friends, I’m back with another post based on my learning and exploring AI and how to fit work as network engineers. In today’s post I want to share the first (of what there is probably many) “buttons”, which I think we should all be aware of and how the impact on our use of AI and AI tools. I already feel excitement in the room. After all, a network engineer is not like more than Enhancement of the knob In the network for good performance. And that’s what we’re going to do here. Fine fine -tuning for tools that will help us to be effective.
First up, the desired renunciation of responsibility or two.
- There are so many buttons in AI. (Shocker, I know.) So if you all like this kind of blog post, I would like to return to other posts where we look at other “buttons” and settings in AI and how they work. Well, I’d like to come back as soon as I understand them. 🙂
- Jerk Any setting We have tools can have dramatic effects on results. This includes an increase in the AI resource consumption, as well as increasing hallucinations and reducing the accuracy of information that will return from your challenges. He warned himself. As in all AI things, go and explore and experiment. But do it in a safe laboratory environment.
For today’s experiment I use LMSTUDIO running locally on my laptop rather than public or model AI hosted cloud. For more information about why I like LMMSTUDIO, check out my last blog and create a Netai playground for AI agency.
Enough settings, let’s go!
Impact of working memory size, aka “context”
Let me set the scene.
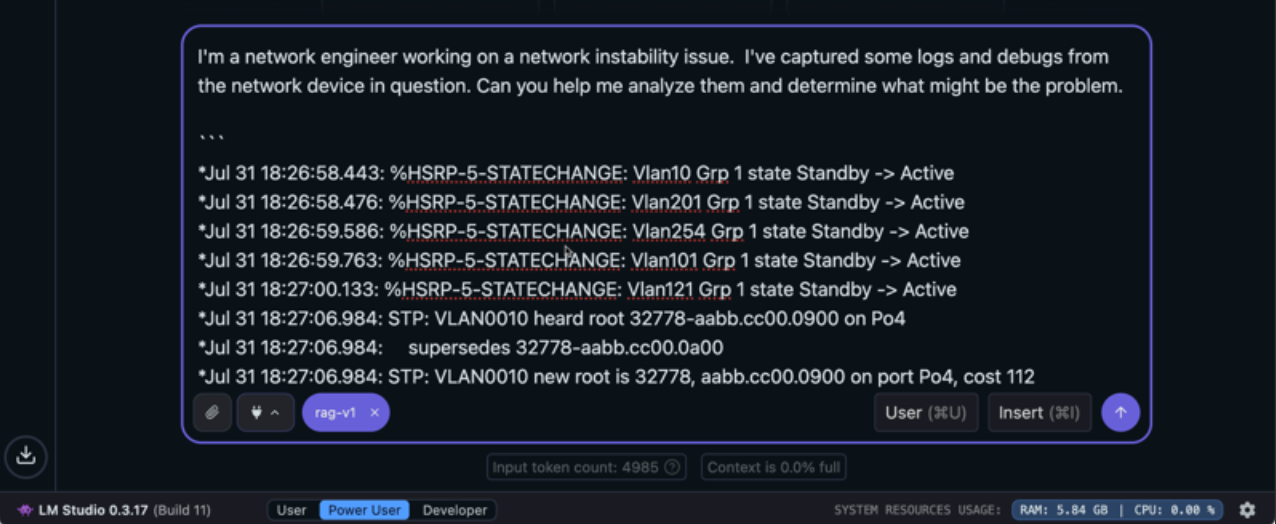
You are in the middle of troubleshooting. Someone postponed or noticed instability at the point of your network and you were assigned a joyful task to get to its bottom. You have captured some protocols and relevant tuning information and it is time to go through it to find out what it means. But you also used AA tools to be productive, 10 times your work, impress your boss, you know All things That is happening.
So you decide to find out if AI can help you work faster through data and get to the root of the problem.
You burn the local AI assistant. (Yes, Local – Bee Know What is in Ladice messages? It is best to keep it all safe on your laptop.)
You tell him what you are doing and put the log in the report.

After you get about 120 lines of protocols, hit Enter, kick your legs, stretch around Arnold Palmer on a refreshing drink, and wait for AI magic to happen. But before you can sip That icy tea and lemonadeYou can see that it appeared on the screen:

Oh my.
“AI has nothing to say.”!?! How could it be?
Did you find a question so trouble that AI can’t handle it?
No, that’s not a problem. Check out the useful error message that LMSTUDIO has launched back:
“They try to keep the first 4994 tokens when they context overflowing.” The model is a load with a context length of only 4096 tokens, which is not enough. Try loading a model with a larger length of context or to provide a shorter input. ”
And we got to the root of this perfectly scripted story and demonstration. Every AI tool has a limit to how much “working memory” it has. The technical term for this working memory is “context length. ” If you try to send more data to the AI AI tool before fit the length of the context, you hit this error or something similar.
The error message shows that the model was “loaded with a context length of only 4096 tokens”. What is the “token”? The answer that could be a topic of a completely different blog post, but for now I just know that “chips” are a unit of size for the length of context. And the first thing that is done when you are a challenge to AI tool is that the challenge is converted to “tokens”.
So what do we do? The message gives us two possible options: we can include the length of the model context or we can provide a shorter input. Sometimes it’s not a big problem to provide a shorter input. But at other times, as when we deal with large protocol files, this option is not practical – all data is important.
It’s time to turn the button!
It is the first option to load a model with a larger context length, that’s our Nerd button. Let’s turn it.
Within the LMSTUDIO, go to “My Models” and click to open the interface for the model configuration.

You will get a chance to display all the buttons that have AI models. And as I mentioned, there are many.

The one we care about right now is the length of context. We can see that the default length of this model is 4096 tokens. However, it supports up to 8192 tokens. Let’s maximize it!

LMSTUDIO provides a useful warning and a likely reason why the model does not create the maximum. The length of the context requires memory and sources. And the increase to a “high value” can affect performance and use. So if this model had a maximum length of 40,960 chips (the Qwen3, which I use sometimes, has such a maximum maximum), you may not just want to maximize it correctly. Instead, increase it a little at a time to find a sweet place: the length of the context sufficiently large for work, but not excessive.
As network engineers we are used to fine -tuning buttons for timers, image size and many other things. That’s right in our alley!
Once you have updated the length of the context, you will need to “eject” and “reload” the settings model to manifest. But as soon as it’s done, it’s time to take advantage of the change we’ve made!

And look at it, with the context window width, AI assistant was able to go through the protocols and give us a nice write about what they show.
I especially like the shadow that threw my way: “… Consider finding help from … a qualified network engineer.” Well played, ai. He played well.
But besides a bruised ego, we can continue to solve problems with AI assisted with something similar.

And we offer races. We were able to use the OU AI assistant:
- Process a meaningful love for logos and tuning data to identify possible
- Create a timeline of the problem (which will be very useful in the documents for analyzing tickets to Help Desk and Root))
- Identify some other steps that we can take in our efforts to eliminate problems.
All stories must end …
And so you have it, our first button AI Nerd – length of context. Let’s see what we learned:
- The AI models have “working memory”, which is again the “length of context”.
- The length of the context is measured in “tokens”.
- Ophontes AI model times will support a higher context length than the default settings.
- Increasing the length of context will require multiple resources, so make changes slowly, not only maximize it.
Now, depending on what AI you are using, you may not be able to adjust the length of the context. If you use public AI as Chatgpt, Gemini or Claude, the length of the context will depend on the signature and models to which you have access. However, there is a length of context that will take into account how much “working memory” AI has. And to be aware of this fact and its impact on how you can use is important. Although the button in question is behind the lock and the key. 🙂
If you liked this view under the hood of AI and would like to learn more about more options, please let me know in the comments: Do you have a favorite “button” you want to turn? Share it with us. Uxt time!
PS … If you would like to read about the use of LMSTUDIO, my friend Jason Belk put together a free tutorial called Run Your LLM on the local level of free and lightness that can start very quickly. Look!
Sign up for Cisco U. | Join Cisco Learning Network today.
Learn with Cisco
X| Fibers Facebook | LinkedIn | Instagram| YouTube
Wears #Ciscou and#CiscocertJoin the conversation.
Read more:
Creating a Netai playground for agency experimenting AI
Take a break AI and let the agent recover the network
Share:
(Tagstotranslate) agent AI