

This blog divides the available prices and deployment and tools that scalable support, AI deployment with cost knowledge.
When you build with AI, it calculates every decision – especially in terms of costs. When you are just enough or scalp the business applications, the last thing you want is an unpredictable price or a rigid infrastructure that slows you down. Azure Openai is designed with regard to it: sufficiently flexible for an early experiment, strong enough for global commitment and prices to match how you actually use it.
From startups to Fortune 500, more than 60,000 customers choose Azure AI foundry, not only for accessing basic and reasoning models – but because they encounter that they are, the possibilities of deployment and prices that are aligned for real business. It is more than just AI – it is about ensuring innovation sustainable, scalable and accessible.
This blog divides the available prices and deployment and tools that scalable support, AI deployment with cost knowledge.
Flexible price models that match your needs
Azure Openai supports three different price models designed to meet different workload profiles and business requirements:
- Standard– Apron or variable workload where you want to pay only for what you use.
- Secured—Form high -performance performance sensitive applications they require consist of permeability.
- Dose-For extensive tasks that can be asynchronously processed at a discounted rate.
Each approach is designed to scalance with you – UNDERS verify use or deployment across business units.

Standard
Tea Standard The deployment model is ideal for teams that want flexibility. Based on the tokens consumed, the API calls are charged, helping to optimize budgets during a period of lower use.
Best for: Development, prototyping or production workload with variable demand.
You can choose between:
- Global deployment: Clean optimal latency across geographical areas.
- Openai data zones: For greater flexibility and control over privacy and data residence.
With all deployment withdrawals, the data are stored at rest in Azure Selected areas of your source.
Dose
- Tea Dose The model is designed for highly efficient and extensive conclusions. Tasks are sent and processed asynchronously, with answers returned within 24 hours – up to 50% less than global standard prices. Batch also contains extensive support for workload for processing mass requirements with lower costs. The scale of your massive dose queries with minimal friction and effectively process extensive workload to shorten the processing time, with a 24 -hour target turnover, up to 50% lower costs than the global standard.
Best for: Tasks with a large volume with flexible needs of latency.
Typical use are:
- Extensive data processing and content generation.
- Data pipe.
- Evaluation of the model across extensive data sets.
Customer in Action: Ontada
Ontada, McKesson, used the Batch API to convert over 150 million cancer documents into structured knowledge. When using LLMS across 39 cancer types, they unlocked 70% of previously inaccessible data and shortened the document processing by 75%. For more information, see Ontad’s case study.
Secured
Tea Secured Providing a model reserved throughput through temporary permeability (PTU). This allows for stable latency and highly threshput-help for production uses that require real-time performance or processing. Liabilities can be hourly, monthly or annually with corresponding discounts.
Best for: Enterprise load with a predictable requirement and the need consists of performance.
Normal use of boxes:
- Search and processing scenarios with high volume documents.
- Operation Call Center with predictable traffic hours.
- Retail assistant with natural high permeability.
Customers in Action: Visier and UBS
- Visier Built “Vee”, General Ai Assist, which serves up to 150,000 users per hour. Using PTU, improved response time three times compared to the models paid by AS-You-go and reducing calculation costs in the scale. Read the case study.
- UBS Created “UBS red”, secure platform AI supporting 30,000 employers across regions. PTU allowed the bank to provide reliable performance with the dedication of the region across Switzerland, Hong Kong and Singapore. Read the case study.
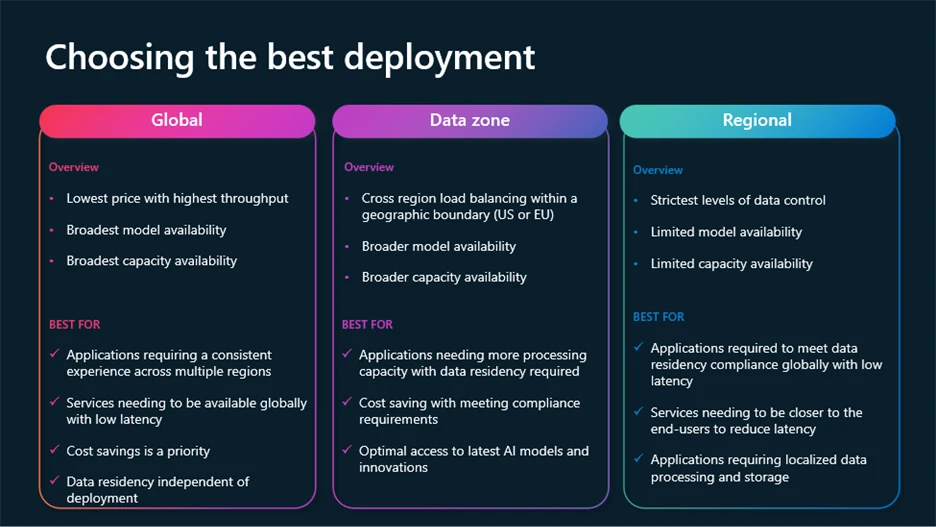
Types of deployment for standard and provided
If you want to meet growth, requires control, compliance and cost optimization, Azure Openai more support types of deployment:
- Overall: The most effective cost of the global requirements for Azure infrastructure, with stay in the area of rest.
- Regional: Maintains data processing in a specific area of Azure (28 available today), with a data stay in peace and processing in the selected area.
- Data zones: Offers the middle ground – the fiction remains in geographical zones (EU or USA) for further compliance with the regulations without full overhead costs.
Global and data zone deployment are available standard, provided and batch models.
Dynamic features will help you reduce the cost of optimizing power
Now there are several dynamic new features to help you achieve the best results for lower costs.
- Model Router for the Azure AI foundry: Model Chat for AI deployment that automatically selects the best basic cottage model that responds to the challenge. The model router, ideal for various use of boxes, provides high performance and at the same time saves computing costs, if possible, everything packed as the only model of the model.
- Batch support for extensive workload: Bulk processes for lower cost applications. Effectively process extensive workloads to shorten the processing time, with a 24 -hour target switch, 50% lower costs than the global standard.
- A commission permeability of dynamic spilling: Provides trouble -free overflows for your high -performance applications when applied. Transport burst the service.
- Call: Built -in optimization for repeatable patterns of challenges. It accelerates responsibility, permeable permeability and helps significantly reduce the cost of the token.
- Dashboard Azure Openai Monitoring: Continuously monitor performance, use and boundability in deployment.
If you want to learn more about these features, and how to use the latest innovations in the Azure AI Foundry models, follow this session from Build 2025 to optimize GEN AI applications.
In addition to the flexibility of prices and the deployment of Azure Openai integrates with Microsoft cost management tools, which provide teams with visibility and control over their AI expenditure.
Abilities include:
- Real -time cost analysis.
- Creating and notification of the budget.
- Support for multi-cloud shors.
- Assign costs and backward feedback by a team, project or department.
These tools help to finance and engineering teams remain harmonized – it makes it easier to understand the use of Treds, monitoring optimization and avoiding survival.
Built -in integration with Azure ecosystem
Azure Openai is part of a large ecosystem that contained:
This integration simplifies the life cycle of building, adaptation and management of AI solutions. You do not need to connect separate platforms-and this means a quick time to the value and less headaches.
A trusted foundation for a business AI
Microsoft has committed itself to allow AI that is safe, private and secure. This commitment is reflected not only in the field of politics but also in the product:
- Secured future initiative: Understanding of safety approval as proposed.
- Responsible Principles of AI: Applied across tools, documentation and workflows.
- Compliance Enterprise-Grade: Data residence coverage, access control and audit controls.
Start with Foundry Azure AI
(Tagstranslate) ai